

Muzyczny wirus korony królów
Jeden z akapitów poniższego tekstu został napisany przez sztuczną inteligencję. Co ciekawe, naprawdę niełatwo go wskazać1. Czy imitacja człowieka przez maszynę może być twórcza? A może w artykuł wkradł się wirus? Zastanówmy się nad tym, jak imitacja kształtuje naszą kulturę. Badaczki i badacze z kręgu memetyki uważają, że nieustannie naśladujemy zachowania innych2. W ten sposób powstają memy, czyli podstawowe jednostki informacji kulturowej, które replikują się i podlegają transmisji w drodze komunikacji werbalnej, wizualnej oraz elektronicznej. W kulturze mogą one przybierać różne formy, takie jak idee, umiejętności, zachowania czy zwroty. Część badaczy porównywała je również do „wirusa umysłu”3, który przenosi się z jednego gospodarza na drugiego.
Przez pryzmat memu możemy również ujrzeć ciekawe oblicze świata muzyki. Na początek przyjmijmy, że mem muzyczny to każda jednostka informacji muzycznej lub dotyczącej muzyki, która jest kopiowana, przekazywana i rozprzestrzeniana poprzez imitację. Dostrzeżemy wtedy na przykład, że w transmisji i propagacji memów muzycznych skutecznie pomaga nam technologia. Weźmy chociażby rekomendacje i playlisty serwisu streamingowego Spotify, dzięki któremu setki milionów słuchaczek i słuchaczy codziennie poznaje nową muzykę. W niniejszym artykule zrobimy krok do tyłu i zastanowimy się nad tym, w jaki właściwie sposób systemy rekomendacji przyczyniają się do replikowania muzycznych memów. Przyjrzymy się algorytmowi word2vec i sprawdzimy, jak wirtualna maszyna przewiduje nasz gust muzyczny. Później przekonamy się, w jaki sposób sztuczna inteligencja, zaprzężona obecnie do rekomendacji Spotify, może pomóc nam zrozumieć memetycznego wirusa muzyki.
Mimesis
Podobno astronom Carl Sagan powiedział, że jeśli ktoś chciałby upiec szarlotkę od zera, najpierw musi wynaleźć wszechświat. Oczywiście nie dowiemy się już, czy takie tłumaczenie swoich słów uznałby za trafne. Możemy więc zabawić się w głuchy telefon i potraktować niniejszą sentencję jako komentarz na temat złożoności otaczającego nas świata. Co to znaczy „upiec szarlotkę od zera”? Czy powinniśmy używać w tym celu kupionych w sklepie jajek? A może założyć własny kurnik? Przydałby się też sad, w którym wyhodujemy własne jabłka, rzecz jasna z własnoręcznie zasadzonych jabłoni. Skąd weźmiemy jednak sadzonki?
Problem upieczenia szarlotki od zera daje nam ciekawy wgląd w świat muzyki. Wyobraźmy sobie, co trzeba zrobić, aby stworzyć piosenkę całkowicie od zera. Na pewno wypadałoby zbudować własny instrument. Później musimy wymyślić indywidualny system harmoniczny, żeby nie opierać się na gotowych wzorcach. Poza tym piosence przyda się tekst. Czy możemy jednak korzystać z gotowych słów? Najlepiej byłoby wymyślić własny język. Nie powinniśmy też opierać się na gotowych schematach. Z drugiej strony, jeśli zrezygnujemy z formy zwrotkowej, nasz wytwór przestanie być piosenką. Problem tworzenia od zera zjada własny ogon. W końcu stworzenie czegoś z niczego złamałoby najbardziej elementarne prawa fizyki, czyli zasady zachowania energii oraz informacji.
Pozostaje więc przyjąć założenie, że każda twórczość (oraz każdy inny obiekt, proces czy zjawisko) to co najwyżej przekształcenie bytów już istniejących w nowe formy. Oczywiście nie jest to żadna odkrywcza wiadomość. Ślady takiego poglądu możemy znaleźć już w starożytności. W tym przypadku mówimy o klasycznym, szerokim pojęciu imitacji – mimesis. W języku starogreckim słowo mimesis (gr. μιμήσις) oznaczało imitację, naśladownictwo i podobieństwo. Stanowi jedno z ważniejszych pojęć w historii estetyki, poczynając od Platona. Już w Dialogach pojawia się myśl, że wszystko, co mówimy, może być tylko pewnym naśladownictwem lub obrazem4. Możemy odważnie zinterpretować te słowa Platona właśnie w kontekście poglądu, że wszystkie wytwory ludzkiej kultury są w pewnym stopniu przetworzeniem czegoś już istniejącego, a nie całkowitą kreacją „od zera”.
Memetyka
Pokłosie myśli Darwinowskiej w badaniu kultury doprowadziło do powstania koncepcji pozagenetycznej, ewoluującej informacji kulturowej. Badaczem związanym z popularyzacją takiego podejścia, jak również twórcą określenia „mem”, jest amerykański biolog Richard Dawkins. W swojej popularnonaukowej książce Samolubny gen (1976) badacz po raz pierwszy opisuje memy jako replikatory kulturowe działające analogicznie do genów. Tak jak gen jest jednostką ewolucji biologicznej, tak mem stanowi jednostkę ewolucji kulturowej. Jako przykłady ewoluujących przejawów ludzkiej kultury Dawkins podaje między innymi język, melodie i idee5. Nazwę „mem” wywodzi od mimesis i właśnie przy pomocy naśladownictwa tłumaczy sposób replikacji memów:
Tak jak geny rozprzestrzeniają się w puli genowej, przeskakując z ciała do ciała za pośrednictwem plemników lub jaj, tak memy propagują się w puli memów, przeskakując z jednego mózgu do drugiego w procesie szeroko rozumianego naśladownictwa. Jeśli naukowiec przeczyta lub usłyszy o jakimś dobrym pomyśle, przekazuje go współpracowniczkom i studentkom. Wspomina o nim w artykułach i na wykładach. O propagowaniu się nośnej idei można powiedzieć wtedy, gdy przenosi się ona z mózgu do mózgu.6
Memy kojarzą nam się dziś przede wszystkim z kulturą internetową. Co ciekawe, Dawkins i inny wpływowy memetyk – Daniel Dennett – twierdzą, że popularne rozumienie terminu „mem” ogranicza jego szersze pole znaczeniowe. Podkreślają, że mem internetowy to tylko jeden z podgatunków memu rozumianego jako uniwersalna jednostka ewoluującej informacji kulturowej7. Można w tym miejscu powiedzieć, że pojęcie memu samo w sobie przeszło już memetyczną ewolucję i wymknęło się spod kontroli swojego oryginalnego twórcy. Sam proces memetycznego przekształcenia najlepiej obrazuje gra w głuchy telefon. Kiedy zaczniemy rozgrywkę z hasłem „żarna”, może ono przebiegać w następujący sposób: żarna > czarna > shoarma > szarmant > armat > wariat. W tym wypadku każdej kolejnej kopii towarzyszy błąd, który prowadzi do powstania nowej iteracji pierwotnej informacji.
Na stronie internetowej „Journal of Memetics – Evolutionary Models of Information Transmission” możemy znaleźć informacje o różnych kierunkach badawczych memetyki. Pierwszy z nich kojarzony jest głównie z nazwiskiem filozofa umysłu i memetyka, Daniela Dennetta, który porównuje obecność memów w ludzkim umyśle do programowania komputera. Uważa on człowieka za gatunek hybrydyczny – organizm biologiczny zasiedlony przez memy, które dają nam software, czyli świadomość, a z kolei geny hardware, czyli mózg8. Memetyczne oprogramowanie człowieka stanowią aktywne informacje kulturowe, które pomagają nam w rozumowaniu, i które Dennett określa jako „narzędzia do myślenia” (thinking tools)9.
Według Dennetta memy walczą o replikację w bezładnym procesie naturalnej selekcji na takich samych zasadach jak geny10. W ten sposób kreśli on analogię między „rywalizacją” genów w puli genetycznej a „rywalizacją” informacji kulturowych o miejsce w naszych umysłach. Należy jednak podkreślić, że zarówno w ewolucji biologicznej, jak i kulturowej nie znajdziemy odgórnego, inteligentnego projektu11. Podążając za myślą Dennetta, uznanie, że memy działają świadomie i mają jakiś własny cel byłoby niepoprawną antropomorfizacją. Jeśli jednak pewien mem niczym komputerowy wirus będzie obdarzony czymś w rodzaju instrukcji „zreplikuj mnie”, która skutecznie dotrze do podświadomego umysłu odbiorczyni, będzie miał on wtedy większą szansę się rozprzestrzenić. W związku z tym te memy, które nie dążą do replikacji, powoli znikają z kultury i ustępują miejsca tym, które o nią „zabiegają”. Możemy więc myśleć o otaczających nas memach w taki sposób, jakby faktycznie kierowały się pragnieniem replikacji12.
Co więcej, Dennett za Dawkinsem uważa, że memy należy traktować jak struktury żywe, które są fizycznie urzeczywistniane jako potencjał czynnościowy w układach nerwowych ludzi na całym świecie13. Mem to jednak w tym wypadku wciąż przede wszystkim abstrakcyjna informacja, która równie dobrze może być zapisana na innym fizycznym nośniku. Cytując Dennetta: „Wiersz nie składa się z atramentu”14. Jego treść jest niezależna od tego, czy zapiszemy go w ludzkiej pamięci jako pewien wzorzec w mózgu, na kartce papieru dzięki pisanemu alfabetowi, czy też na płycie CD jako ciąg zer i jedynek.
Z kolei brytyjska memetyczka Susan Blackmore wyróżnia trzy replikatory. Pierwszy z nich to gen – ewoluująca informacja genetyczna zapisana w DNA lub RNA. Organizmy żywe to, za Dawkinsem15, „maszyny przetrwania” wykorzystywane w naturalnej selekcji genów16. Drugi replikator to mem – ewoluująca informacja kulturowa zapisana w ludzkich umysłach. Blackmore nazywa człowieka „maszyną memową”. W jej wizji memy istnieją w przekazie informacji kulturowej między ludźmi i są zapisywane wyłącznie w ich umysłach17. Kiedy zaś do świata memów wkrada się technologia i maszyny zaczynają kopiować, modyfikować i selekcjonować cyfrowe informacje, mamy do czynienia z memem technologicznym, czyli właśnie trzecim rodzajem replikatora, któremu Blackmore nadała nazwę „tem”. „Maszyną temową” może być więc wytwór technologiczny, który umożliwia naturalną selekcję temów. Za przykład maszyny temowej badaczka uznaje algorytmy wyszukiwania Google’a18.
Memetyka jest wciąż bardzo młodą oraz aktywnie rozwijającą się dziedziną. Interesuje ona przede wszystkim kognitywistki, biolożki ewolucyjne, informatyczki oraz kulturoznawczynie. Jej podstawowe pojęcia takie jak mem czy imitacja wciąż podlegają znaczeniowej ewolucji. Również ukuta przez Blackmore kategoria „temu” nie zyskała w memetyce popularności. Badacze decydują się na przyjęcie pewnych definicji, w ramach których mogą poszerzać zasięg oddziaływania memetyki na inne, dojrzalsze dziedziny nauki. Wiele pionierskich i interdyscyplinarnych tekstów o tej tematyce można znaleźć w internetowym wydaniu „Journal of Memetics”.
Memetyka muzyki
W tej interesującej bazie znajdziemy między innymi artykuł Replicating Sonorities: Towards a Memetics of Music autorstwa Stevena Jana, muzykologa z Uniwersytetu w Huddersfield. Jan próbuje zarysować pewną propozycję elementarnych problemów dla memetyki muzyki, odwołując się do różnych nauk pomocniczych związanych z muzykologią19. Dwa główne problemy opisane w artykule to organizacja memów w kulturze oraz strukturze muzycznej. Autor prezentuje analizy wybranych fragmentów muzycznych, podkreślając jednocześnie swoją świadomość tego, że dla większości odbiorczyń i odbiorców muzyka nie funkcjonuje jako zbiór nut, a raczej jako pewne holistyczne i niejednoznacznie ustrukturyzowane doświadczenie.
Mimo braku jednoznacznego wzorca memu muzycznego Jan wskazuje na znaną muzykologom ewolucję stylów w zachodniej muzyce komponowanej na osi barok – klasycyzm – romantyzm. Autor stawia tezę, że ewolucja stylu muzycznego w skali makro jest możliwa dzięki ewolucyjnej aktywności memów. Na potrzeby swojej analizy przyjmuje założenie dwoistej natury memu: memotyp – odpowiednik genotypu – to pojęcie odwołujące się do memu samego w sobie jako wzorca aktywności neuronalnej, zaś femotyp – odpowiednik fenotypu – odnosi się do zbioru zachowań i produktów związanych z przetrwaniem memu. W przypadku memów muzycznych przykładami femotypu będą takie czynności jak zapisywanie, dyrygowanie czy wykonywanie muzyki oraz artefakty, na przykład nuty czy nagrania20. Ze względów pragmatycznych Jan decyduje się analizować wyłącznie memy femotypiczne.
To, że takie memy nie ograniczają się do żadnego pojedynczego nośnika danych, utrudnia również jednoznaczne wskazanie podstawowego memu muzycznego. Rozwiązań tego problemu można zapewne udzielić tak wielu, jak odpowiedzi na pytanie „Czym jest muzyka?”. Możliwe jest rozwiązanie tego metodologicznego impasu za pomocą dwóch różnych narzędzi. Po pierwsze, zamiast bezowocnie spekulować na temat ontologii, po prostu przyjmuje się taką użytkową jednostkę memu muzycznego, która pozwala przeprowadzić najciekawsze rozumowanie. Jan, jako specjalista od muzyki komponowanej, za swoją jednostkę przyjmuje motyw muzyczny zawarty w partyturze. Muzyka zapisana za pomocą nut opiera się na ściśle określonych parametrach i ma długą tradycję teoretyczną, która dostarcza wielu wskazówek przy analizie.
Drugie narzędzie to ominięcie problemu doboru podstawowej jednostki memu muzycznego poprzez wprowadzenie pojęcia mempleksu. Memy, podobnie jak geny, zyskują przewagę w doborze naturalnym, jeśli funkcjonują w sprzyjającym otoczeniu. Możemy więc mówić o chromatycznym pochodzie sopranu jako o jednym z memów składających się na mempleks tristanowski21. Mempleksami nazywamy zatem zbiory memów służące do użytecznego określenia złożonych kompleksów kulturowych. Wewnątrz nich możemy dopatrzeć się wielu częściowo niezależnych memów, które jednocześnie zapewniają sobie przyszły byt dzięki współistnieniu22.
Memetyczna historia muzyki
Z kolei w swojej książce The Memetics of Music Steven Jan analizuje memy muzyczne na podstawie partytur głównie zachodnioeuropejskiej muzyki komponowanej od późnego renesansu do pierwszej połowy XX wieku. Jako pierwszy przykład omawia frazę zawartą oryginalnie w taktach 54–55 Koncertu na instrument klawiszowy Es-dur op. 7 nr 5 (W C59) Johanna Christiana Bacha oraz w taktach 14–15 Mozartowskiego Uprowadzenia z Seraju23. Mimo drobnych różnic w zapisie najważniejsze jest wyraźne podobieństwo brzmieniowe obu fragmentów. Nie jest to sytuacja wyjątkowa. W historii zachodnioeuropejskiej muzyki komponowanej można przecież znaleźć mnóstwo różnych przykładów kopiowania motywów, fraz, kadencji czy form.
Jan, zafascynowany Dawkinsowską biologią ewolucyjną opowiedzianą z perspektywy samolubnego genu, proponuje opisanie historii muzyki w ten sam sposób. W takiej narracji dzieła muzyczne składają się z grup częściowo niezależnych memów, a każdy z nich dba o własną replikację. Co więcej, Jan mówi o tym, że symboliczne znaczenia i odniesienia ukryte w danych fragmentach muzycznych pełnią funkcję intertekstualnych hiperłączy24 w konceptualnej przestrzeni25. Projekt Jana wymaga więc przestudiowania jak największej liczby partytur z kanonu zachodnioeuropejskiej muzyki komponowanej w celu odnalezienia i zmapowania wszystkich przypadków imitacji, inspiracji, transkrypcji, kontrafaktury czy nawet nieświadomego kopiowania. Dzięki temu będziemy w stanie lepiej zrozumieć głębokie, ewolucyjne przemiany muzyki komponowanej.
Czy takie karkołomne zadanie bez sprawnej pomocy narzędzi komputerowych nie przyniesie jednak więcej pracy niż korzyści? Zgromadzenie partytur i wprowadzenie danych do systemu cyfrowego stanowi zaledwie pierwszy krok. Prawdziwa trudność leży w odnalezieniu faktycznych prawidłowości i opisaniu wszystkich gałęzi memetycznej ewolucji. Na szczęście w ostatnich dekadach nastąpił ogromny rozwój wirtualnych maszyn specjalizujących się w analizie danych i wychwytywaniu wzorców. To właśnie jedna z dziedzin, w których specjalizuje się sztuczna inteligencja (SI).
Zastosowanie SI
Najważniejszym narzędziem SI do wyszukiwania prawidłowości w zbiorach danych jest machine learning, czyli uczenie maszynowe. Do rozwoju tego typu algorytmów przyczyniły się m.in. dwa czynniki: zdalny dostęp do ogromnych ilości danych oraz zdolność współczesnych komputerów do ich generowania, przechowywania i przetwarzania26. Tu zaczynają się komplikacje z modelem Jana. Przykładowo, aby trafnie opisać ewolucję barokowych figur retorycznych, należy najpierw zrozumieć ich zakodowane znaczenia, których nie da się wywieść z samych partytur. Dopiero wiedza o związkach muzyki i retoryki może doprowadzić do poprawnej interpretacji muzycznej figury krzyża27. Jaki korpus wiedzy muzykologicznej należałoby więc zaimplementować do takiego modelu i w jaki sposób? Przeróżne tradycje analizy i interpretacji często stoją przecież ze sobą w dysonansie. Pozostaje trzymać kciuki za to, że nakarmiony treścią kilku bibliotek muzykologicznych algorytm wyrazi chęć współpracy z algorytmem znającym partytury i będzie w stanie wypluć z siebie coś niesprzecznego wewnętrznie.
W ostatnich latach szczególną skutecznością wykazują się algorytmy oparte na tzw. uczeniu przez wzmacnianie (reinforcement learning). W przypadku tego behawioralnego modelu algorytm działa w nieznanym sobie środowisku, ucząc się metodą prób i błędów. W przeciwieństwie do uczenia nadzorowanego (supervised learning) brak jest tutaj określonych danych wejściowych i wyjściowych. W wyniku analizy danych system otrzymuje informację zwrotną, która prowadzi użytkowniczkę do uzyskania możliwie najlepszego wyniku. Seria właściwych decyzji powoduje wzmocnienie procesu, ponieważ stanowi najlepsze rozwiązanie danego problemu28. Jako przykład może tu posłużyć zastosowanie sztucznej inteligencji w chińskiej grze Go. W 2016 roku, po morderczym treningu obejmującym analizę bazy 30 milionów ruchów zawodowych graczy, program AlphaGo pokonał jednego z najlepszych światowych graczy z wynikiem 4:1. Jego młodszy kuzyn, AlphaGo Zero, znał jedynie podstawowe reguły gry i uczył się wyłącznie na podstawie rozgrywek z samym sobą, bez wiedzy na temat ludzkich strategii. Po zaledwie trzech dniach treningu AlphaGo Zero pokonał najpotężniejszy wówczas na świecie AlphaGo z wynikiem 100:0. Ucząca się sama od siebie sztuczna inteligencja w ciągu 70 godzin osiągnęła większą skuteczność gry niż rozwijana przez ponad 2500 lat strategia ludzka29. Znając więc moc uczenia maszynowego, można uwierzyć, że nawet niedouczony kulturowo i teoretycznie algorytm wyciągnie z bazy partytur muzycznych interesujące wnioski.
W tym miejscu warto zaznaczyć, że między programem sztucznej inteligencji AlphaGo Zero a algorytmami służącymi do analizy muzycznej istnieją oczywiście głębokie różnice. Przede wszystkim celem AlphaGo Zero była wygrana w grę Go, która posiada pewien jasno ustalony zbiór reguł. Jaki zatem byłby cel algorytmu analizującego muzykę jako zjawisko kulturowe, którego zasady nie są opisywalne w ten sposób? Linearny kanon muzyczny fałszywie sugeruje, że ludzkość poczyniła znaczące postępy na drodze do stworzenia ostatecznego, absolutnego arcydzieła, które „zakończy muzykę”. Zadaniem naszego algorytmu nie byłaby wygrana w grę, a jedynie wyszukiwanie wzorców i wymodelowanie ścieżki muzycznej ewolucji we wskazanej bazie danych. Może się jednak okazać, że wszystkie dostępne partytury muzyki komponowanej dostarczą zbyt małą ilość danych, aby sztuczna inteligencja mogła popisać się swoimi zdolnościami analitycznymi. Znane, internetowe archiwum International Music Score Library Project zawiera zbiór druków muzycznych ponad 160 tysięcy różnych utworów. Z perspektywy użytkowniczki to bardzo dużo, ale dobra SI potrzebuje znacznie więcej informacji.
Dla porównania, wykupiona przez Spotify w 2014 roku baza Echo Nest zawiera dane dotyczące ponad 35 milionów piosenek30. Co ciekawe, niewielka część bazy, czyli jeden milion piosenek, została udostępniona do publicznego użytku, co oznacza, że można swobodnie przeprowadzać na niej naukowe analizy31. W tym wypadku nie mówimy oczywiście o zapisie nutowym. Dane z Million Song Dataset zawierają za to inne ciekawe informacje, takie jak tonacja utworu, „taneczność” (danceability), liczba odrębnych elementów formy czy czas trwania. Prawdopodobnie najbardziej oryginalnym parametrem jest hotttnesss, który mierzył popularność artystki lub artysty w danym czasie32. Przykładowo w 2010 roku, czyli w czasach swojej memicznej świetności, piosenka Never Gonna Give You Up Ricka Astley’a uzyskała we wynik 80% w tym wskaźniku.
Algorytmy Spotify
Projekt Echo Nest rozpoczął się w MIT Media Lab. Firma gromadziła dane dotyczące utworów muzycznych przy pomocy takich technik jak web crawling czy data mining, czyli zautomatyzowanych procesów gromadzenia danych dostępnych w internecie33. Stosowała również algorytmy do identyfikowania i analizy muzyki. Streamingowy gigant nie przejął jednak narzędzi Echo Nest w celu prowadzenia badań naukowych. Zgromadzone informacje wykorzystano do rozwinięcia systemu rekomendacji muzycznych opartego na algorytmach. Na platformach blogowych poświęconych nowym technologiom można znaleźć wiele artykułów, których autorki i autorzy, bazując na własnym researchu, starają się przedstawić zarys działania algorytmów Spotify i właśnie na podstawie takich źródeł przeprowadzam poniższą analizę.
Spotify zainteresował się rekomendacjami muzycznymi w 2010 roku. Na wczesnym etapie nad wszystkim czuwał jeden człowiek, inżynier Erik Bernhardsson34. Początkowo skłonił się on w stronę najprostszej i jednocześnie bardzo skutecznej metody collaborative filtering. Jak wyjaśnia w swoim artykule Sophia Ciocca, metoda ta zestawia ze sobą preferencje użytkowniczek i użytkowników w liniowy sposób. Przyjmijmy proste dane: użytkowniczka I lubi piosenki A, B i C, a użytkowniczka II często słucha B, C i D. Collaborative filtering bez trudu wykryje podobieństwo preferencji słuchaczek I i II. Pierwszej z nich poleci piosenkę D, drugiej zaś piosenkę A35.
Spotify testował również inne rozwiązania. Być może najbardziej kreatywne z nich to polecanie nowej muzyki na podstawie podobieństwa okładek albumów36. Okazało się jednak, że taki sposób daje oczekiwany rezultat jedynie w gatunku minimal techno. Znacznie bardziej skutecznym narzędziem okazały się analizy „obrazów” utworów, tzw. raw audio models. Za pomocą konwolucyjnych sieci neuronowych (convolutional neural network, CNN)37 analizowane są spektrogramy, na podstawie których podejmowane są próby kategoryzacji utworów. Co ważne, w CNN dane traktowane są przestrzennie (w domenie czasu, częstotliwości lub innej przestrzeni matematycznej)38.
Kolejnym modelem rekomendacji używanym przez Spotify jest przetwarzanie języka naturalnego (Natural Language Processing, NLP). Na podstawie metadanych NLP wyszukuje teksty ze źródeł internetowych, takich jak artykuły, newsy, blogi czy czasopisma. Następnie analizuje, w jaki sposób opisywane są określone utwory i artyści, wskazuje, jacy inni artyści i utwory pojawiają się w tym samym kontekście oraz wyodrębnia związane z nimi frazy kluczowe39. Poprzez ustalenie, jacy inni artyści i utwory są opisywane za pomocą podobnego języka, Spotify może grupować utwory i polecać te, które mogłyby spodobać się danej użytkowniczce.
Kluczowe zastosowanie w rekomendacjach Spotify mają modele oparte na algorytmie word2vec. Pierwsze badania dotyczące word2vec zostały opublikowane w 2013 roku przez zespół badawczy Google’a prowadzony przez czeskiego programistę Tomáša Mikolova40. Według Bernhardssona zespół uczenia maszynowego w Spotify pracował wtedy nad modelem collaborative filtering, a w ciągu kilku tygodni od jego wypuszczenia zaimplementował także algorytm word2vec41. Niedługo potem, w roku 2014, firma zakupiła wspomnianą wcześniej bazę danych Echo Nest. To właśnie te kroki doprowadziły do powstania najsłynniejszej rekomendującej funkcji Spotify: Discover Weekly, czyli cotygodniowej listy 30 piosenek tworzonych indywidualnie dla milionów aktywnych użytkowniczek i użytkowników. Aby zrozumieć system rekomendacji Spotify, przyjrzymy się z bliska mechanizmom działania word2vec.
Algorytm word2vec
Word2vec to jedno z narzędzi SI wykorzystywanych przez różne portale i aplikacje do tworzenia systemów rekomendacji. To sieć neuronowa, której uogólnione działanie polega na określaniu wielowymiarowych relacji semantycznego podobieństwa między słowami. Elementarnym zagadnieniem w word2vec jest sposób określania znaczenia słów. Wybrano w tym celu mało intuicyjne, ale jednocześnie bardzo skuteczne podejście – semantykę dystrybucyjną. Jej tradycja badawcza rozpoczęła się jeszcze w latach 50. XX wieku, kiedy to językoznawca John R. Firth napisał: „You shall know a word by the company it keeps” („Rozpoznasz słowa po ich towarzystwie”)42. Semantyka dystrybucyjna zakłada, że znaczenie każdego słowa można skutecznie określić na podstawie jego dystrybucji, czyli kontekstów, w których ono się pojawia. W tej perspektywie słowa nie mają żadnego inherentnego znaczenia. Cały język tworzy zaś coś na kształt semantycznej mapy, a znaczenie słów zapisywane jest w postaci wektorów, które określają ich położenie. Zastosowanie tej nieintuicyjnej teorii znaczenia doprowadziło do prawdziwego przełomu w dziedzinie przetwarzania języka naturalnego.
Skuteczność narzędzi opartych na semantyce dystrybucyjnej bierze się stąd, że każde słowo w danej bazie otrzymuje swoją bardzo dokładną reprezentację wektorową, która pozwala na przeprowadzanie działań matematycznych. Nazwa tej techniki to word embedding, czyli osadzanie słów. Dzięki niej przechodzimy do istoty działania word2vec – arytmetyki słownej. Dla przykładu skorzystajmy z darmowego kalkulatora semantycznego na stronie WebVectors43. Na początek wybieramy jedną z dostępnych baz słów, na których trenowano algorytm – anglojęzyczną Wikipedię. Następnie wpisujemy wszystkie słowa, które chcemy dodać oraz odjąć. Przeprowadzamy pierwsze działanie:
Paris − France + Poland = …Warsaw (0.80)!
Ten prosty przykład obrazuje potencjał word2vec. Dzięki wektorom słownym algorytm jest w stanie zrozumieć, że kiedy odejmiemy od Paryża Francję i dodamy Polskę, otrzymamy Warszawę. Sieć zauważa, że relacja wektorowa Paryża i Francji jest bardzo zbliżona do relacji Warszawy i Polski. Oczywiście wiedzę danego algorytmu zawsze ogranicza rozmiar zastosowanej bazy danych i dlatego w przypadku Wikipedii nie możemy spodziewać się szczególnie wnikliwych wniosków ze świata muzyki. Mimo wszystko spróbujmy:
Chopin − piano = …greatest (0.21), Voltaire (0.20)!
Otrzymaliśmy dwa wyniki opatrzone wartościami liczbowymi, które zawsze mieszczą się w przedziale od 0.00 do 1.00. Można powiedzieć, że jest to współczynnik trafności danej odpowiedzi. Faktyczne działania matematyczne odbywają się na wektorach usytuowanych w wielowymiarowej przestrzeni i po złożeniu wszystkich wektorów znajdujemy się w pustym miejscu. W takim przypadku sieć informuje nas o najbliższych wynikach. Pochylmy się jednak nad samą treścią tych odpowiedzi: Chopin bez fortepianu jest po prostu „the greatest”, a poza tym najbliżej mu do wybitnego francuskiego pisarza. Czy to oficjalna odpowiedź sztucznej inteligencji na pytanie „Kim byłby Chopin, jeśli nie kompozytorem”?


Animacje z platformy TensorFlow, źródło: projector.tensorflow.org
Kolejne interesujące działanie, które możemy przeprowadzić na wektorach słownych, to równanie: A ma się do B tak, jak C ma się do D. Tym razem skorzystajmy z dwóch różnych baz danych – anglojęzycznej Wikipedii oraz bazy Google News:
Haydn -> Mozart = Adele ->…Lady Gaga 0.58 (English Wikipedia), Leona 0.47 (Google News)!
Trenowany na Wikipedii word2vec uważa, że Haydn ma się do Mozarta tak, jak Adele do Lady Gagi. Coś w tym jest. Bardziej frapuje za to odpowiedź z Google News. Kim jest Leona? To wojowniczka z niesamowicie popularnej gry komputerowej League of Legends. Skąd wzięła się taka odpowiedź? W zasadzie sektor gier komputerowych powoli zajmuje miejsce dawnego MTV.
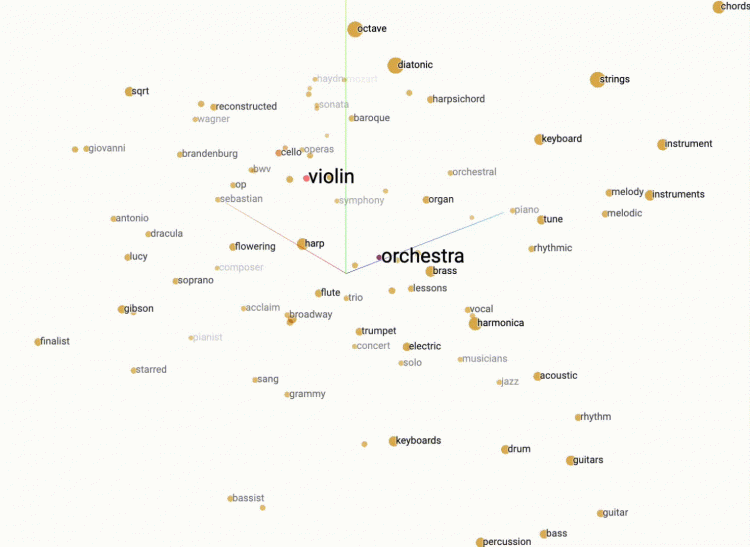
Znacznie łatwiej zrozumieć wektory słowne i przestrzenie, w których funkcjonują dzięki wizualizacjom osadzania słów. Poniższe grafiki przedstawiają wybrane słowa „Chopin” oraz „violin” wraz z ich najbliższymi sąsiadami w przestrzeni platformy o otwartym kodzie źródłowym TensorFlow (projector.tensorflow.org). Niniejsze grafiki ukazują skupiska słów, które według word2vec występują w podobnych kontekstach. Zgodnie z założeniami semantyki dystrybucyjnej im bliżej siebie znajdują się dane słowa, tym bliższe jest również ich znaczenie.
Jakie zastosowania może zatem znaleźć algorytm word2vec w systemie rekomendacji muzycznych Spotify? Rąbka tajemnicy uchylili w swojej prezentacji z 2015 roku związani ze Spotify inżynierowie Chris Johnson i Edward Newett, którzy wskazali dwa główne modele zastosowania algorytmu: w analizach opisów artystów i utworów oraz w analizach zależności między słuchanymi przez użytkowniczki utworami44. W pierwszym modelu omówiony wyżej mechanizm NLP wyszukuje w internecie teksty i przeprowadza analizę języka użytego do opisów artystek i utworów – również pod kątem tonu i przekazywanych nastrojów45 – oraz identyfikuje kluczowe frazy. Chociaż szczegóły dotyczące dalszego przetwarzania danych nie są publicznie dostępne, możemy oprzeć się na analizach innych autorek i autorów46, którzy sugerują, że na tym etapie kluczową rolę odgrywa grupowanie danych w tzw. „wektory kulturowe”47. Wektor kulturowy to wielowymiarowy model kulturowych konotacji danego obiektu zbudowany na podstawie ogromnej ilości danych. Mówiąc dokładniej, do każdego artysty i utworu przypisywany jest szereg codziennie zmieniających się „top terms”, czyli najmocniej związanych z nimi określeń. Każdemu „top term” towarzyszy również waga w skali od 0 do 1, którą możemy rozumieć jako stopień prawdopodobieństwa, że ktoś opisze daną artystkę czy piosenkę za pomocą tego właśnie określenia48. Jako przykład może posłużyć tabelka Echo Nest cultural vectors z artykułu Briana Whitmana, gdzie fraza „dancing queen” ma przypisaną wagę 0,0707, „mamma mia” – 0,0622, „disco era” – 0,0346, „swedish pop” – 0,0296, a „enduring appeal” 0,028049. Model Spotify używa „top terms” i wag w celu stworzenia wektorowej reprezentacji utworu, która umożliwia znalezienie podobnych do siebie piosenek50. W ten właśnie sposób Spotify jest w stanie wybrać utwory, które mogłyby spodobać się danemu użytkownikowi.
W drugim modelu word2vec traktuje utwory jak słowa, a sekwencję utworów słuchanych przez użytkowniczkę jak dokument51. Pozwala to na tworzenie wektorów, które reprezentują utwory osadzone w określonych kontekstach. Kontekst może stanowić playlista czy nawet szerzej – historia słuchania52. Im częściej dane dwa utwory słuchane są w podobnych kontekstach, tym bliżej będą ich współrzędne. W ten sposób możemy łatwo zidentyfikować podobne utwory oraz przeprowadzić operacje arytmetyczne, aby znaleźć wektor, który reprezentuje każdego użytkownika53. Aby wygenerować rekomendacje muzyczne, wystarczy przeanalizować reprezentacje utworów sąsiadujących z tymi, które już polubił54.
Muzyczne konteksty
Wykraczając poza modele oparte na algorytmie word2vec, inny rodzaj map muzycznych kontekstów możemy znaleźć w projekcie Spotify – Every Noise at Once. Zaprojektowana przez Glenna McDonalda dwuwymiarowa mapa określa relacje pomiędzy ponad 4,5 tysiącami gatunków muzycznych, pośród których m.in. znajdziemy: Macedonian indie, NWOTHM, Christian trap czy Polish experimental electronic. Co ciekawe, zaraz obok gruzińskiej muzyki alternatywnej znajduje się polski hip-hop. Na portalu możemy znaleźć informację o rozmieszczeniu gatunków na mapie: „Dół jest bardziej organiczny, góra jest bardziej mechaniczna i elektryczna; lewa strona jest gęstsza i bardziej nastrojowa, z kolei prawa jest żywsza i bardziej skoczna”55. Możemy wyciągnąć wniosek, że mapa stanowi rodzaj systemu rekomendacji – jeśli odpowiada nam dany gatunek muzyczny, jest prawdopodobne, że polubimy też te sąsiadujące. Po kliknięciu w nazwę gatunku możemy odsłuchać jego próbki dźwiękowej, a następnie przejść do mapy związanych z nim artystek i artystów. W tym przypadku bliskość między twórcami ma sugerować ich gatunkowo-stylistyczne podobieństwo. Platforma wykorzystuje API Echo Nest do pozyskiwania danych dotyczących gatunków oraz API Spotify Web do odtwarzania próbek utworów56.
Mapa Echo Nest powstała na podstawie tysięcy tajemniczych danych i zależności. Takie właśnie zależności determinują sposób replikacji muzycznych memów w Spotify. Czy systemy muzycznych rekomendacji mają jak najwierniej odzwierciedlać rzeczywistość? A może mają po prostu umożliwiać jak najskuteczniejszą replikację memów muzycznych? Przekonajmy się, czy sztuczna inteligencja zaprzężona obecnie do rekomendacji Spotify może nam pomóc zrozumieć memetycznego wirusa muzyki.


Screenshoty z platformy Every Noise at Once, źródło: everynoise.com
Systemy rekomendacji
Zasadniczo systemy rekomendacji oparte są na dwóch kategoriach: użytkowników oraz obiektów. Użytkowniczki i użytkownicy wpisują swoje podstawowe dane, takie jak imię, wiek, płeć czy narodowość. W przypadku Spotify obiekty to utwory muzyczne, którym towarzyszy baza jawnych i ukrytych danych, na przykład tytuł, wykonawca, kompozytorka, gatunek, nastrój, tempo, rok produkcji oraz wytwórnia muzyczna. Odsłuchując utwór za utworem, zaczynamy budować historię użytkowniczki. Możemy wyobrazić sobie, że nawet na tej podstawie po odsłuchaniu stu dobrze skatalogowanych utworów algorytm rekomendacji może dać całkiem niezły wynik.
Mechanizm działania systemów rekomendacji jest jednak bardziej skomplikowany. Na temat pojedynczego użytkownika można powiedzieć znacznie więcej niż to, kto jest jego ulubionym wykonawcą. Sieci neuronowe i uczenie maszynowe to duet, który specjalizuje się w wykrywaniu różnych prawidłowości. Jeśli tylko zbudujemy odpowiednio długą historię użytkownika, takie prawidłowości nie mogą umknąć systemowi rekomendującemu. Miło jest myśleć, że mamy niepowtarzalny gust muzyczny. W dniu 30 czerwca 2020 roku, Spotify miał 299 milionów aktywnych użytkowniczek i użytkowników miesięcznie57. Ile znajduje się wśród nich osób, które lubią to, co my?
Pozwólmy sobie na odrobinę spekulacji. Wydaje się, że system rekomendacji potrafi odnaleźć pewną wydeptaną ścieżkę i zorientować się, kiedy nią podążamy. Spotify może na przykład zarejestrować historie 10 tysięcy użytkowniczek i użytkowników, którzy po przesłuchaniu dyskografii The Beatles, The Who, Jimiego Hendrixa i Erica Claptona zdecydowali się zainteresować twórczością Pink Floyd. Zatem kiedy dziesięć tysięcy pierwsza użytkowniczka przesłucha wszystko od Please Please Me aż po Happy Xmas, warto polecić jej The Piper at the Gates of Dawn.
Wystarczy podobieństwo jednej właściwości użytkownika, na przykład kraju pochodzenia, aby wygenerować trafną rekomendację. Ten sam mechanizm dotyczy rekomendacji obiektów. Piosenka Kazika Twój ból jest lepszy niż mój może zainteresować przede wszystkim tych, którym najbliższa jest sytuacja polityczna w Polsce. Można więc polecić ją mieszkankom i mieszkańcom naszego kraju.
Wydeptane ścieżki rekomendacji nie muszą podążać od utworu do utworu. Załóżmy, że w piątkowe wieczory większość słuchaczek i słuchaczy w wieku 15–60 lat decyduje się na muzykę nieco szybszą i weselszą niż zwykle. Na przykład zwolenniczki Squarepushera skłonią się ku My Red Hot Car, a słuchacze Björk, zamiast wsłuchać się w losss, zatańczą do Big Time Sensuality. W tym przypadku podobieństwo słuchaczek i słuchaczy polega na tym, że ich całkowicie różne wektory wykonują podobne zwroty na płaszczyznach tempa, nastroju oraz pory słuchania utworów. Nie mamy jednak dowodów na to, że tak zaawansowane analizy są już faktycznie przeprowadzane. Przekopując się przez olbrzymie, wciąż rosnące biblioteki danych Spotify, sztuczna inteligencja nieustannie pracuje nad tym, aby jak najwięcej użytkowniczek i użytkowników odsłuchiwało nie tylko coraz więcej piosenek, ale także coraz więcej dobieranych specjalnie do ich nastrojów reklam. Pamiętajmy, że Spotify optymalizuje muzyczne rekomendacje pod kątem korporacyjnego zysku, a nasze wzruszenia czy euforie to zaledwie efekt uboczny. Nasze uzależnienie od słuchania jest zatem ich sukcesem.
Algorytmy Spotify znają twoje preferencje znacznie lepiej niż ty. Co gorsza, masz do wyboru tylko dwie opcje: muzykę, którą uwielbiasz ty lub muzykę, którą uwielbiają inni. Całkiem prawdopodobne jest to, że Spotify chce, abyśmy przesłuchali ich cały katalog58. Wyobraźmy sobie sytuację, w której bazy i algorytmy Spotify służą jako podstawa do badań w rodzaju memetycznej historii muzyki w koncepcji Stevena Jana. Oczywiście miała ona przedstawić przemiany stylistyczne w muzyce na podstawie zapisu nutowego, a Spotify posługuje się zupełnie innym rodzajem danych. Istotą takiej historii muzyki jest jednak przyjęcie perspektywy samolubnego memu. Dzięki danym Spotify moglibyśmy opisać ewolucyjne przemiany innego rodzaju niż Janowskie, na przykład w sposób epidemiologiczny monitorować rozwój earworms, czyli piosenek o wyjątkowej zdolności memetycznej reprodukcji. Moglibyśmy też badać zmiany preferencji muzycznych określonej grupy społecznej czy też opisywać szczegółowe historie recepcji każdej pojedynczej piosenki.
Idąc o krok dalej, możemy też przyjąć, że algorytmy wykorzystywane w systemie rekomendacji Spotify, a wśród nich omówiony wyżej word2vec, stanowią doskonały przykład zdefiniowanych przez Susan Blackmore maszyn temowych i temów. Mamy tu do czynienia ze zjawiskiem przechowywania, kopiowania, modyfikacji i selekcji informacji cyfrowych (playlist muzycznych) nie w ludzkich umysłach, ale w środowisku sztucznej inteligencji. Temowe maszyny decydują o tym, które utwory replikują się lepiej, a które odchodzą w zapomnienie. Czy takie maszyny działają w służbie człowieka? Blackmore twierdzi, że każdy samodzielny replikator walczy o własne przetrwanie i działa w swoim własnym interesie. Jej zdaniem memy i temy w swojej replikacji polegały do tej pory na ludziach, jednak ludzkość nie jest dla ich rozwoju niezbędna59. Badaczka zwraca uwagę na to, że w niedalekiej przyszłości naturalna selekcja temów może odbywać się wyłącznie przy udziale maszyn60. Oczywiście ludzie mają tutaj wciąż coś do powiedzenia, a każdy system rekomendacji to cybernetyczna fuzja maszyny i człowieka. Podążając jednak za myślą Blackmore, niekontrolowany rozwój memów i temów niesie ze sobą potencjalnie istotne ryzyko związane z przyszłością sztucznej inteligencji. Dzięki dogłębnej analizie historii słuchania setek milionów użytkowniczek i użytkowników moglibyśmy mieć wgląd w metody replikacji oraz proces ewolucji memów i temów.
Możliwości badawcze wydają się zatem nieograniczone. Jest tylko jeden problem – Spotify nie udostępnia swoich danych. Póki co pozostaje więc albo zdobyć pracę w Spotify, albo pobrać darmowy Million Song Dataset i budować pierwsze modele. Nie zatrzymamy już rozwoju wirusa muzyki, ale pracujmy nad szczepionką, która pozwoli nam kontrolować jego rozprzestrzenianie się w przyszłości!
Krótkie wprowadzenie do tematu sztucznej inteligencji w dziennikarstwie, zob.: Nicole Martin, Did a Robot Write This? How AI Is Impacting Journalism, „Forbes”, 8.02.2019, www.forbes.com/sites/ nicolemartin1/2019/02/08/did-a-robot-write-thishow-ai-is-impacting-journalism, dostęp tu i dalej
23.10.2020. ↩Zob. Daniel Dennett, From Bacteria to Bach and Back: The Evolution of Minds, W. W. Norton & Company, New York 2017; Susan Blackmore, Imitation and the Definition of the Meme, „Journal of Memetics – Evolutionary Models of Information Transmission”, vol. 2, 1998, http://cfpm.org/jomemit/1998/vol2/blackmore_s.html; Richard Dawkins, Samolubny gen, tłum. Marek Skoneczny, Prószyński Media, Warszawa 2006. ↩
Zob. Richard Dawkins, Viruses of the Mind, w: Dennett and His Critics: Demystifying Mind, red. Bo Dahlbom, Wiley-Blackwell, Oxford 1995, s.13–27; Richard Brodie, Wirus umysłu, tłum. Piotr Turski, TeTa Publishing, Łódź 1997 ↩
Platon, Dialogi, tłum. Władysław Witwicki, Tower Press, Gdańsk 2000. s. 222. ↩
Richard Dawkins, Samolubny gen, dz. cyt., s. 169 ↩
Tamże, s. 244. ↩
Zob. Richard Dawkins w rozmowie z Mahmoodem Fazalem, Richard Dawkins Told Us What He Thinks About Memes, 2018, www.vice.com/en_us/article/d35ana/richard-dawkins-told-us-what-he-thinksabout-memes; If Brains Are Computers, Who Designs the Software? With Daniel Dennett, 2017, www.youtube.com/watch?v=TTFoJQSd48c. ↩
Daniel Dennett, Consciousness Explained, Little, Brown and Company, Boston 1991, s. 209–226. ↩
Tenże, Dźwignie Wyobraźni i inne narzędzia do myślenia, Copernicus Center Press, Kraków 2016, s. 14. ↩
Tenże, Odczarowanie. Religia jako zjawisko naturalne, tłum. Barbara Stanosz, Państwowy Instytut Wydawniczy, Warszawa 2008, s. 10 ↩
Tenże, From Bacteria to Bach and Back…, dz. cyt., s. 138. ↩
If Brains are Computers…, dz. cyt. ↩
D. Dennett, Consciousness Explained, dz. cyt., s. 254; R.Dawkins, Samolubny gen, dz. cyt., s. 147. ↩
If Brains are Computers…, dz. cyt. ↩
Zob. R. Dawkins, Samolubny gen, dz. cyt. ↩
Susan Blackmore, Temes: An Emerging Third Replicator, National Humanities Center, 2010, https://nationalhumanitiescenter.org/on-thehuman/2010/08/temes-an-emerging-third-replicator. ↩
Taż, The Meme Machine, Oxford University Press, Oxford 2000. ↩
Taż, Temes: An Emerging Third Replicator, dz. cyt ↩
Steven Jan, Replicating Sonorities: Towards a Memetics of Music, „Journal of Memetics – Evolutionary Models of Information Transmission”, vol. 4, 2000, http://cfpm.org/jom-emit/2000/vol4/jan_s.html. ↩
Tamże. ↩
Tamże. ↩
Tamże. ↩
Steven Jan, The Memetics of Music: A Neo-Darwinian View of Musical Structure and Culture, Ashgate Publishing, Aldershot/Burlington 2007, s. 1–2. ↩
Tamże, s. 2. ↩
Tamże, s. 71–72. ↩
Zob. Ethem Alpaydin, Introduction to Machine Learning, The MIT Press, Cambridge/Massachusetts/London 2010, s. 1–2. ↩
Józef Majewski, Theologiae proxima. Słowo o muzyce jako teologii, „Znak”, nr 744, 2017, www.miesiecznik.znak.com.pl/theologiae-proxima-slowo-omuzyce-jako-teologii. ↩
Judith Hurwitz, Daniel Kirsch, Machine Learning for Dummies, John Wiley & Sons, Inc., Hoboken 2018, s. 16. ↩
Demis Hassabis, David Silver, AlphaGo Zero: Starting From Scratch, DeepMind Blog, 2017, www.deepmind.com/blog/article/alphago-zerostarting-scratch. ↩
Ryan Faughnder, Spotify Buying The Echo Nest to Improve Music Discovery, „Los Angeles Times”, 2014, www.latimes.com/entertainment/envelope/cotown/la-et-ct-spotify-buying-theecho-nest-20140306-story.html. ↩
Zob. baza Million Song Dataset: www.
millionsongdataset.com. ↩Zob. Brian Whitman, How Music Recommendation Works — And Doesn’t Work, Variogr.am, 2012, https://notes.variogr.am/2012/12/11/how-music-recommendation-worksand-doesnt-work ↩
The Echo Nest: The Data Behind Personalized Playlists, „Open Forum”, 2015, www.hbs.edu/openforum/openforum.hbs.org/goto/challenge/understand-digital-transformationof-business/the-echo-nest-the-databehind-personalized-playlists.html. ↩
Więcej informacji o Eriku Bernhardssonie można znaleźć tutaj: www.erikbern.com/about.html. ↩
Sophia Ciocca, How Does Spotify
Know You So Well?, „Medium”, 2017, www.medium.com/s/story/spotifysdiscover-weekly-how-machinelearning-finds-your-new-music19a41ab76efe. ↩Erik Bernhardsson, Music Discovery at Spotify, prezentacja na temat systemu polecania muzyki Spotify przedstawiona na konferencji MLConf NYC 2014, www.slideshare.net/erikbern/musicrecommendations-mlconf-2014, s. 31. ↩
Konwolucyjne sieci neuronowe mają zastosowanie w oprogramowaniu do rozpoznawania obrazów. Zob. Sumit Saha, A Comprehensive Guide to Convolutional Neural Networks — The ELI5 Way, „Towards Data Science”, 2018, www.towardsdatascience.com/a-comprehensive-guide-toconvolutional-neural-networks-theeli5-way-3bd2b1164a53. ↩
S. Ciocca, dz. cyt. ↩
Tamże. ↩
Zob. Computing Numeric Representations of Words in a High Dimensional Space, https://patents.google.com/patent/US9037464B1/en. ↩
Odpowiedź Erika Bernhardssona, How Did Spotify Get So Good At Machine Learning?, „Forbes”, 2017, www.forbes.com/sites/quora/2017/02/20/howdid-spotify-get-so-good-at-machinelearning. ↩
John R. Firth, A Synopsis of Linguistic Theory, 1930–1955, w: Studies in Linguistic Analysis, Special Volume of the Philological Society, red. tegoż, Basil Blackwell, Oxford 1957, s. 11, tłum. własne. ↩
WebVectors: Semantic Calculator, http://vectors.nlpl.eu/explore/embeddings/en/calculator/. ↩
Chris Johnson, Edward Newett, From
Idea to Execution: Spotify’s Discover Weekly, DataEngConf (obecnie Data Council), 2015, www.slideshare.net/mrchrisjohnson, slajdy nr 33 i 34. ↩Zob. Erik Cambria, Dipankar Das, Sivaji Bandyopadhyay, Antonio Feraco, A Practical Guide to Sentiment Analysis, Springer, London 2017. ↩
Zob. S. Ciocca, dz. cyt.; Ulku Guneysu, How Is Spotify’s Thriving Recommendation System Becoming a New Advertising Platform?, „Medium”, 2019, www.medium.com/swlh/how-is-spotifysthriving-recommendation-systembecoming-a-new-advertisingplatform-a2b97ffe2012; Vincent Ngo, Spotify’s Recommendation Engine, 2019, https://ischools.org/resources/Documents/Discipline%20of%20organizing/Case%20Studies/SpotifyNgo2019.pdf. ↩
Warto wspomnieć, że koncepcja „wektorów kulturowych” i „top terms” pojawiła się już w modelu muzycznych rekomendacji wypracowanym przez Echo Nest. Zob. B. Whitman, dz. cyt. ↩
S. Ciocca, dz. cyt. ↩
B.Whitman, dz. cyt. ↩
S.Ciocca, dz. cyt ↩
C. Johnson, E. Newett, dz. cyt., slajd nr 34. ↩
Weiqi Tong, From Word2Vec to Song2Vec: A Music Recommendation Experiment, „Medium”, 2018,
www.medium.com/@weiqi_tong/from-word2vec-to-song2vecan-embedding-experimentation9215279c9d7a. ↩Ramzi Karam, Using Word2vec for Music Recommendations, „Towards Data Science”, 2017, www.towardsdatascience.com/using-word2vec-for-musicrecommendations-bb9649ac2484. ↩
Jan Bussieck, Demystifying Word2Vec, „Deep Learning Weekly”, 2017, www.deeplearningweekly.com/blog/demystifying-word2vec. ↩
Every Noise at Once, http://everynoise.com, tłum. własne. ↩
Spotify for Developers, Every Noise at Once, https://developer.spotify.com/community/showcase/every-noise/ ↩
Więcej statystyk Spotify jest dostępnych na stronie: www.newsroom.spotify.com/company-info. ↩
Akapit napisany przez algorytm GPT-2 i przetłumaczony przez autora niniejszego artykułu dzięki www.talktotransformer.com. Na swojej stronie internetowej www.openai.com/blog/better-language-models twórcy z firmy badawczej OpenAI wyjaśniają, że GPT-2 wyszkolono po to, aby przewidywał następne słowo na podstawie poprzednich słów w otrzymanym tekście. Algorytm otrzymał dane pochodzące z ośmiu milionów stron internetowych. ↩
Susan Blackmore, Genes, Memes and Temes/Tremes, www.susanblackmore.uk/memetics/genes-memes-andtemestremes. ↩
Susan Blackmore, It’s Too Late to Give Machines Ethics – They’re Already Beyond Our Control, „The Guardian”, 2015, www.theguardian.com/commentisfree/2015/sep/18/machines-ethics-control-artificialintelligence-google-demis-hassabis. ↩